OS: MAC
참고: 👉 점프 투 파이썬 - 라이브러리 예제 바로가기
044. 객체를 파일로 저장하고 불러오려면? ― pickle(피클)
- pickle 파일은 사람이 읽을 수 없음 (이진 형식)
- 다른 환경/버전에서 로드 시 호환성 주의
- 신뢰할 수 없는 pickle 파일은 보안상 위험
| 구분 | 설명 | 예시 | 결과 |
| 모듈명 | 파이썬 객체(리스트, 딕셔너리, 클래스 등)를 파일로 저장하거나 복원하는 모듈 |
import pickle | - 프로그램의 실행 결과를 파일로 저장 - 머신러닝 모델, 데이터셋 임시 저장 - 세션/설정 값 유지 |
| 객체 저장 (직렬화) | 객체를 이진 파일로 저장 (dump) |
import pickle data = {'name': 'Yul', 'age': 29, 'job': 'developer'} with open('data.pkl', 'wb') as f: pickle.dump(data, f) |
결과값이 출력되지 않음(정상) # 다만, data.pkl 파일이 생성되고, 그 안에 data 객체가 저장됨 |
| 객체 불러오기 (역직렬화) | 저장된 객체를 다시 메모리로 불러오기 (load) |
import pickle with open('data.pkl', 'rb') as f: loaded_data = pickle.load(f) print(loaded_data) |
{'name': 'Yul', 'age': 29, 'job': 'developer'} |
| 비고 | 파일 모드 요약 | 'wb' 'rb' |
write binary (저장할 때) read binary (불러올 때) |
라이브러리 예제 문제:



045. 객체 변경에 따른 오류를 방지하려면? ― copyreg(카피렉)
- pickle로 저장한 객체가 클래스 구조 변경 후에도 안전하게 복원되도록 직렬화 규칙을 등록하는 모듈.
| 구분 | 설명 | 예시 | 결과 |
| 모듈명 | pickle로 저장된 객체가 나중에 클래스 구조가 바뀌어도 오류 없이 복원되게 도와주는 모듈 |
import copyreg | - 사용자 정의 클래스 직렬화 시 유용 - 라이브러리 코드나 대형 프로젝트에서 사용 - 유지보수나 버전 관리 시 안정성 확보 가능 |
| 사용 목적 |
클래스 구조(속성, 초기화 방식 등)가 변경되더라도 이전 pickle 데이터를 안전하게 불러오기 위함 |
— | - pickle과 함께 사용 시 버전 호환성 보장 |
| 기본 구조 |
이 타입(type) 의 객체를 저장(직렬화)하고 불러올(역직렬화) 때 어떤 저장 방식(dump_function) 과 복원 방식(load_function) 을 쓸지 지정하라”는 뜻이야. |
copyreg.pickle (type, dump_function, load_function) # 객체를 직렬화할 거야 (타입, 저장 방식, 불러올 방식) |
- 객체 저장 및 불러올 때 사용할 함수등록 - 객체의 직렬화/역직렬화 규칙을 직접 정의 |
| 예시 | 사용자 정의 클래스(Person)를 pickle로 저장했다가, 나중에 클래스 구조(예: 속성, 초기화 인자)가 변경될 경우 오류가 발생한다. 이런 오류를 방지하면서 객체를 안전하게 저장하고 불러오려면 어떻게 해야 할까? |
import copyreg, pickle class Person: def __init__(self, name): self.name = name # 저장 규칙 정의 def pickle_person(person): return Person, (person.name,) # copyreg에 등록 copyreg.pickle(Person, pickle_person) # 객체 생성 및 저장 p = Person('Yul') with open('person.pkl', 'wb') as f: pickle.dump(p, f) # 파일에서 불러오기 with open('person.pkl', 'rb') as f: loaded = pickle.load(f) # 결과 출력 print(loaded.name) |
Yul |
라이브러리 예제 문제: (문제가 개 길다. 읽다가 전 내용을 까먹을 수준)



046. 딕셔너리를 파일로 저장하려면? ― shelve(셸브)
- shelve는 딕셔너리처럼 쓰는 파일 기반 키-값 저장소.
- 키는 str, 값은 피클 가능한(Pickle-able) 파이썬 객체면 OK.
- 용도: 간단한 설정/캐시/작은 데이터의 영속 저장(프로토타입, 스크립트, 크롤러 캐시 등).
- 플랫폼/파이썬 버전 간 데이터 파일 호환 불가할 수 있음. 같은 환경에서 쓰고 읽는 것을 권장.
| 구분 | 서명 | 예시 | 결과 |
| 모듈명 | 내부적으로 dbm 기반 파일을 사용. |
import shelve | - 간단한 데이터, 설정값, 캐시 등을 프로그램 종료 후에도 유지 가능 - 딕셔너리처럼 접근 (db['key'] = value) |
| 객체 저장/복원 |
딕셔너리 형태로 객체를 파일에 저장 및 복원 |
data = { 'user': 'sophia', 'roles': ['admin', 'editor'], 'prefs': {'theme': 'dark', 'lang': 'ko'}, } import shelve with shelve.open('appstate') as db: for k, v in data.items(): db[k] = v #결과값 출력되지 않음(정상) with shelve.open('appstate') as db: print(db['user']) # 'sophia' print(db['prefs']['lang']) # 'ko' |
sophia ko |
| 객체 불러오기 (읽기) | 저장된 객체를 다시 메모리로 읽어옴. 'r' 모드 사용 가능. |
import shelve with shelve.open('mydata', 'r') as db: print(db['user']) |
{'name': 'Yul', 'age': 29} |
| 'r': 읽기 전용 | 읽기 전용, 없으면 에러 | shelve.open('cfg', flag='r') | |
| 'n': 새로 생성 | 항상 새 파일(기존 덮어씀) | shelve.open('cfg', flag='n') | |
| 딕셔너리처럼 쓰기 / 읽기 / 삭제 | import shelve with shelve.open('mydata') as db: db['count'] = db.get('count', 0) + 1 exists = 'count' in db # 키 존재 확인 del db['count'] # 삭제 |
||
| 가변객체 주의(writeback) 가변값 안전 업데이트 (재할당 방식) |
예상 외 동작 예시 (writeback=False, 기본) 리스트/딕셔너리 같은 가변 객체는 내부 값만 바꾸면 저장이 안 될 수 있음 → writeback=True 옵션 사용 또는 다시 할당 필요. |
with shelve.open('cart') as db: db['items'] = [] # 저장 with shelve.open('cart') as db: items = db['items'] # 리스트 객체 로드 items.append('apple') # 리스트 변경 (파일반영 X) # 해결 1) 다시 할당 db['items'] = items # 재할당로 안전 저장 |
종료 시 자동 저장. writeback=True 없으면 db['items'] = db['items']로 다시 할당해야 반영됨 |
| 가변객체 주의(writeback) | writeback=True 인 경우 | with shelve.open('cart', writeback=True) as db: db['items'] = [] with shelve.open('cart', writeback=True) as db: db['items'].append('apple') # 종료 시 디스크 반영 |
|
| 파일 닫기/동기화 |
파일은 반드시 닫아야 반영됨. with문 사용 시 자동 종료. 수동 저장은 sync() 사용. |
with shelve.open('mydata', writeback=True) as db: db['k'] = {'x': 1} db['k']['x'] = 2 db.sync() # 중간 저장(크래시 대비) |
데이터 안전 저장 (프로그램 도중 크래시 방지) |
| 파일 모드 요약 | 'c': 파일이 없으면 생성/ 있으면 열기 'w': 쓰기 전용 |
import shelve with shelve.open('mydata', flag='c') as db: db['name'] = 'sophia' print(db['name']) # with 블록을 벗어나면 자동 close |
sophia |
| 실무 활용 예) 결과 카운터 / 캐시 |
결과를 파일에 캐싱(cache)하는 데 유용 “한번 계산(또는 요청)한 결과를 다음에 다시 계산하지 않고 저장된 파일에서 빠르게 꺼내 쓰는 방법” |
import shelve, time, hashlib def get_page(url: str) -> str: # (예시) 실제 네트워크 호출 대신 흉내만 time.sleep(0.1) return f"<html>fake content of {url}</html>" def cached_get(url: str) -> str: key = hashlib.sha1(url.encode()).hexdigest() with shelve.open('cache') as db: if key in db: return db[key] #이미 저장된 결과면 그대로 반환 html = get_page(url) db[key] = html # 새로 계산한 결과를 캐시에 저장 return html print(cached_get('https://example.com')) print(cached_get('https://example.com')) # 두 번째는 캐시 히트 |
fake content of https://example.com fake content of https://example.com (두 줄 다 같지만, 첫 번째는 실제 연산(딜레이 0.1초 포함) 두 번째는 캐시에서 즉시 반환되어 빠름.) |
| 비교 (pickle vs shelve) | pickle은 “파일 하나에 객체 하나”를 저장, shelve는 “딕셔너리처럼 여러 개를 키로 나눠 저장”. | - pickle → 한 객체 덤프/로드 - shelve → 여러 객체를 키별로 관리 |
shelve는 내부적으로 pickle을 사용하지만, 사용법은 더 단순하고 직관적 |
라이브러리 예제 문제:


047. 블로그 데이터를 저장하려면? ― sqlite3(시퀄라이트)
- 데이터를 구조적으로, 안전하게, 여러 개의 테이블로 연결해서 저장.
- 블로그/메모 앱/데스크톱 유틸처럼 단일 파일에 구조적 저장 필요 시 사용
- 여러 INSERT → executemany() + 한 번에 commit()
- 적절한 INDEX (검색 조건/정렬에 쓰는 컬럼)
- 대량 작업 전후: PRAGMA journal_mode=WAL 고려, 앱 시작 시 1회 설정
| 구분 | 설명 | 예시 | 결과 |
| 모듈명 | 파이썬 표준 라이브러리의 임베디드 SQL 데이터베이스. 단일 파일(.db)에 테이블/인덱스/트랜잭션을 지원. |
import sqlite3 | - 앱과 함께 배포 쉬움 - 설치 없이 사용 가능 - SQL로 구조적 질의/정렬/필터 |
| DB 연결 | 데이터베이스 파일을 열거나 없으면 생성. 메모리 전용은 ':memory:'. |
conn = sqlite3.connect('blog.db') | blog.db 파일 연결(없으면 생성) |
| 테이블 생성 | 블로그 글/태그/댓글 등 스키마 정의. IF NOT EXISTS 권장. | conn.execute("""CREATE TABLE IF NOT EXISTS posts( id INTEGER PRIMARY KEY, title TEXT NOT NULL, body TEXT, author TEXT, created_at TEXT DEFAULT CURRENT_TIMESTAMP );""") | posts 테이블 생성 |
| 데이터 추가(INSERT) | **바인딩 파라미터(?)**로 안전하게 삽입. | conn.execute("INSERT INTO posts(title, body, author) VALUES(?, ?, ?)", ("첫 글", "내용", "sophia"))conn.commit() | 1행 추가, 커밋 후 저장 |
| 데이터 조회(SELECT) | SELECT ... FROM 테이블명.. 조건/정렬/페이지네이션. fetchall() 조회된 모든 데이터 |
rows = conn.execute("SELECT id, title FROM posts ORDER BY id DESC LIMIT 5").fetchall() | 최근 5건의 (id, title) 목록 |
| 단건 조회 | fetchone()으로 하나만. | post = conn.execute("SELECT * FROM posts WHERE id=?", (1,)).fetchone() | id=1인 행 또는 None |
| 수정 (UPDATE) |
UPDATE 테이블명 SET ... 조건에 맞는 행 갱신. |
conn.execute("UPDATE posts SET title=? WHERE id=?", ("제목 수정", 1)); conn.commit() | 대상 행의 제목 변경 |
| 삭제 (DELETE) |
DELETE FROM 테이블명 ... 조건 삭제. |
conn.execute("DELETE FROM posts WHERE id=?", (1,)); conn.commit() | id=1 행 삭제 |
| 다중 삽입 (executemany) |
여러 행을 한 번에 삽입. | conn.executemany("INSERT INTO posts(title, body, author) VALUES(?, ?, ?)", [("둘째 글","...", "sophia"), ("셋째 글","...", "sophia")]); conn.commit() | 2행 이상 일괄 추가 |
| 데이터 저장 | conn.commit() | INSERT 쿼리문으로 데이터를 입력 시 conn.commit()으로 파이썬 종료해야 데이터 저장됨 | # 커밋 없이 close()를 호출하면 변경된 내용이 모두 사라진다 |
| 사전(dict)처럼 읽기 | row_factory로 컬럼명을 키로 접근. | conn.row_factory = sqlite3.Row post = conn.execute("SELECT * FROM posts LIMIT 1").fetchone() print(post["title"]) |
title 키로 접근 가능 |
| 인덱스 | 자주 조회하는 컬럼에 인덱스 생성. | conn.execute("CREATE INDEX IF NOT EXISTS idx_posts_author ON posts(author)") | author 조건 검색 빨라짐 |
| UPSERT | 고유 제약 위반 시 갱신. | conn.execute("""INSERT INTO posts(id, title, body, author) VALUES(?, ?, ?, ?) ON CONFLICT(id) DO UPDATE SET title=excluded.title""", (1, "새제목", "본문", "sophia")); conn.commit() | id가 있으면 업데이트, 없으면 삽입 |
| 핵심 API & 사용 패턴 |
연결/종료 & 컨텍스트 매니저 | import sqlite3 from pathlib import Path db_path = Path("blog.db") with sqlite3.connect(db_path) as conn: # with: 자동 commit/rollback + close conn.execute("PRAGMA foreign_keys = ON") # FK(외국어) 사용 시 권장 |
SQLite는 기본적으로 외래키 검사 기능이 꺼져 있으니까, 외래키(FK)를 쓰는 테이블을 만든다면 PRAGMA foreign_keys = ON 을 꼭 켜줘야 한다. |
| 스키마 설계(블로그 최소 예시) # 스키마(schema) = 데이터베이스의 구조(Structure) = 어떤 테이블이 있고, 그 안에 어떤 칼럼이 있고, 서로 어떻게 연결되는가”를 정의한 설계도 |
with sqlite3.connect("blog.db") as conn: conn.executescript(""" PRAGMA foreign_keys = ON; CREATE TABLE IF NOT EXISTS posts( id INTEGER PRIMARY KEY, #프라이머리키 title TEXT NOT NULL, body TEXT, author TEXT, created_at TEXT DEFAULT CURRENT_TIMESTAMP ); CREATE TABLE IF NOT EXISTS comments( id INTEGER PRIMARY KEY, post_id INTEGER NOT NULL, body TEXT NOT NULL, author TEXT, created_at TEXT DEFAULT CURRENT_TIMESTAMP, FOREIGN KEY(post_id) REFERENCES posts(id) ON DELETE CASCADE); CREATE INDEX IF NOT EXISTS idx_comments_post ON comments(post_id); """) |
출력값은 없지만 내부에 결과가 생김.(정상) 1. posts 테이블 ㄴid ㄴtitle ㄴbody ㄴauthor ㄴcreated_at 2. comments 테이블 ㄴid ㄴpost_id ㄴbody ㄴauthor ㄴcreated_at 3. 인덱스 ㄴidx_comments_post |
|
| CRUD(크러드) 빠른 흐름 = 데이터를 만들고, 읽고, 고치고, 지우는 모든 기본 동작 |
with sqlite3.connect("blog.db") as conn: # Create(데이터 추가) conn.execute("INSERT INTO posts(title, body, author) VALUES(?, ?, ?)", ("SQLite 시작하기", "내용...", "sophia")) # Read(데이터 조회) rows = conn.execute("SELECT id, title FROM posts ORDER BY id DESC").fetchall() # Update(데이터 수정) conn.execute("UPDATE posts SET title=? WHERE id=?", ("수정된 제목", rows[0][0])) # Delete(데이터 삭제) conn.execute("DELETE FROM posts WHERE id=?", (rows[-1][0],)) |
웹·앱 서비스의 뼈대는 결국 CRUD(크러드). | |
| 페이지네이션 & 검색 = 데이터를 효율적으로 불러오는 기술 = 데이터베이스에 쌓인 수많은 글 중에서, 사용자가 보고 싶은 일부만 빠르고 정확하게 보여주는 기술 |
page, page_size, q = 1, 10, "%SQLite%" offset = (page-1)*page_size with sqlite3.connect("blog.db") as conn: posts = conn.execute(""" SELECT id, title, author, created_at FROM posts WHERE title LIKE ? OR body LIKE ? ORDER BY created_at DESC LIMIT ? OFFSET ? """, (q, q, page_size, offset)).fetchall() |
# LIMIT: 몇 개씩 가져올지 # OFFSET: 어디서부터 가져올지 # 파라미터 바인딩(?) WHERE title LIKE ? → 안전하게 변수값을 SQL에 연결하는 방법 (SQL Injection 방지) |
|
| 트랜잭션(여러 작업을 하나로) = 여러 개의 데이터 작업을 하나의 덩어리(묶음) 로 묶어서, 전부 성공하거나 전부 실패하게 만드는 기능. |
with sqlite3.connect("blog.db") as conn: try: conn.execute("BEGIN") #트랜잭션 시작 # 새 글 작성 post_id = conn.execute(""" INSERT INTO posts(title, body, author) VALUES(?, ?, ?) """, ("트랜잭션 글", "본문 내용", "sophia")).lastrowid # 댓글 추가 conn.execute(""" INSERT INTO comments(post_id, body, author) VALUES(?, ?, ?) """, (post_id, "첫 댓글", "sophia")) conn.commit() # 모든 작업 성공 → 확정(저장) except: conn.rollback() # 중간에 에러 발생 → 모두 되돌림 raise |
트랜잭션의 4대 특징 (ACID) = 데이터의 신뢰성을 보장하는 마지막 방패 |
🔎 LIKE 검색 자세히 보기
| 검색어 | 의미 | 매칭 예시 |
| 'python' | 정확히 "python"인 경우만 | "python" ✅ "python3" ❌ |
| '%python%' | "python"이 포함된 경우 | "파이썬과 sqlite", "python blog" ✅ |
| 'python%' | "python"으로 시작 | "python tutorial" ✅ "my python note" ❌ |
| '%python' | "python"으로 끝남 | "learn python" ✅ "python guide" ❌ |
주의사항 체크리스트
- 항상 바인딩 파라미터(?) 사용 → SQL 인젝션 예방
- 트랜잭션 단위로 commit()/rollback() 관리 (컨텍스트 매니저 권장)
- '스키마 변경(마이그레이션)'은 버전 관리 필요 (예: alembic 대체 스크립트 자체 구현)
- 동시 쓰기 많다면 성능/락 대기 발생 가능 → 소규모/단일 인스턴스에 적합
- sqlite3.Row로 컬럼명 접근을 표준화하면 코드 가독성↑
- 외래키 쓸 때 PRAGMA foreign_keys = ON 잊지 않기
라이브러리 예제 문제:


47번은 SQLite 도구까지 학습한다.
DB Broswer for SQLite’를 내려받아 설치(바로가기) → 실행

아 졸라 헷갈린다.
풀이에 내용이 계속 추가되길래 단순하게 풀이 방식을 올렸는데 거기서 끝이 아니였다.
결국은 저자의 의도대로 코드를 작성해야한다.

다시 SQLite로 돌아와서 → Open Database → blog.db 선택

애플바 상단의 Edit → modify Table → id 의 AI(Auto Increment) 선택 → PRIMARY KEY 우측에 ("id" AUTOINCREMENT) 추가됨

SQLite 상단의 Execute SQL 선택 → 데이터 입력
INSERT INTO blog (subject, content, date)
VALUES ('자동 증가', 'id값이 자동 증가되어 입력됩니다.', '20190831'); → ▶ 실행(Execute all) 버튼선택 → 하단의 메세지 확인
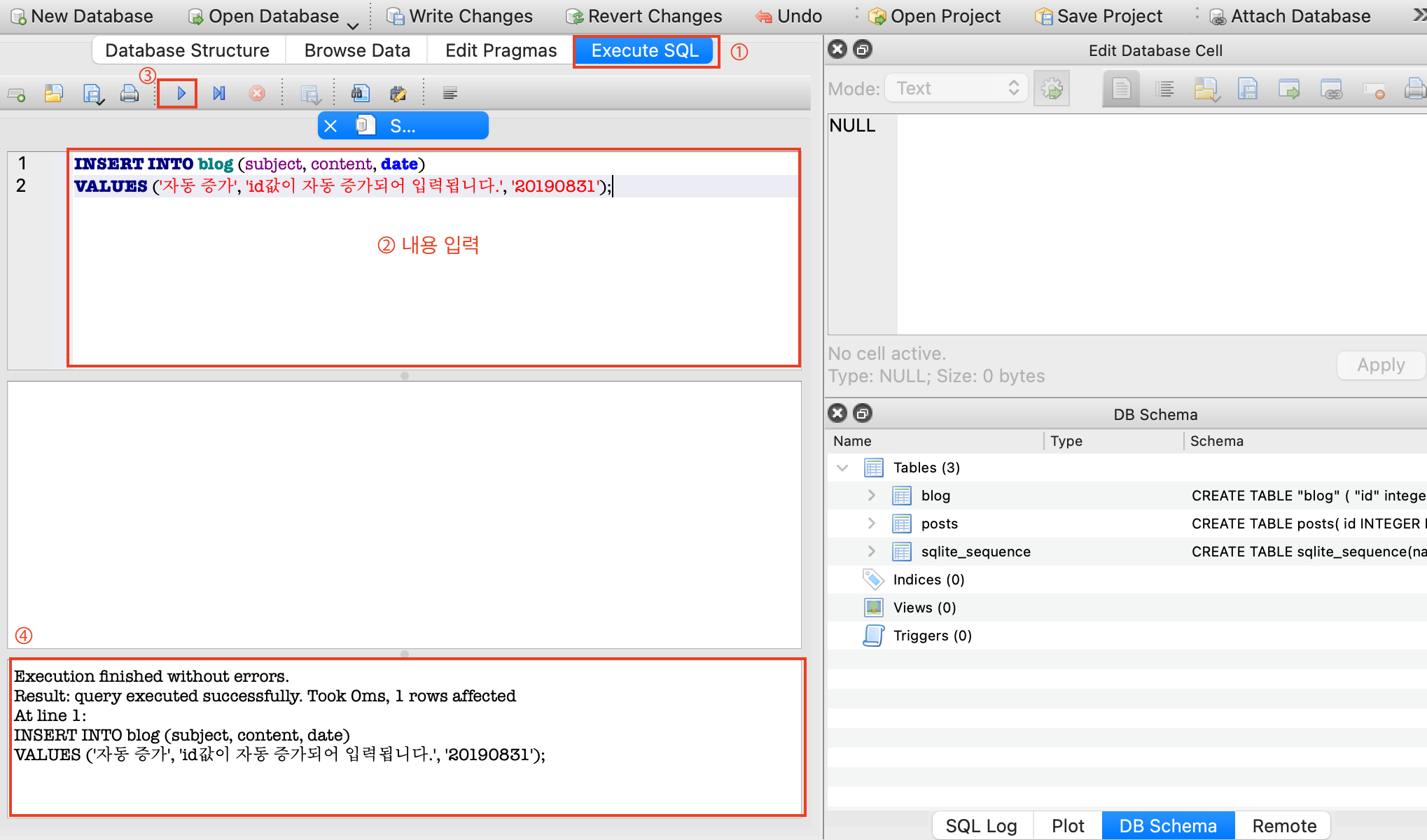
상단 탭 Browse Data 선택 → blog 내용 확인 → id 자동 증가 + 데이터 저장 완료

나머지는 예시에서 다뤘으니.. 오늘은 여기까지하자.
이렇게 지겨운 내용은 처음이다.
아오 멀미나.



